
Edgeformers: Graph-Empowered Transformers for Representation Learning on Textual-Edge Networks
Published:
Edgeformers: Graph-Empowered Transformers for Representation Learning on Textual-Edge Networks[ICLR2023]
1.在什么场景下研究的什么问题(研究背景、目前存在的问题) 2.为什么要研究这个问题(研究的意义、目的) 3.怎么研究的,为什么(研究动机) 4.模型解决了什么问题,又带来了什么问题?
- 研究背景、目前存在的问题
Edge在许多实际的社交/信息网络中是带有丰富信息的,如user-user communications, user-product reviews。但是主流的表征学习模型主要聚焦于节点属性的传播和聚合上,缺乏对edge上的文本语义的利用。虽然存在边缘感知的图神经网络,但它们直接将边缘属性初始化为一个特征向量,这不能完全捕捉到边缘的上下文文本语义。
- 研究意义
文中着眼于两个任务:edge classification & link prediction。①在user-product网络中,edge会是用户对产品的评价,比方说可以将edge分为一星、二星…、五星,可以根据边上的文本(评价)预测用户对产品的满意程度。②例如,在亚马逊评论网络中,我们的目标是根据用户对其他产品的评论和其他用户对该产品的评论来预测用户是否会对产品感到满意。
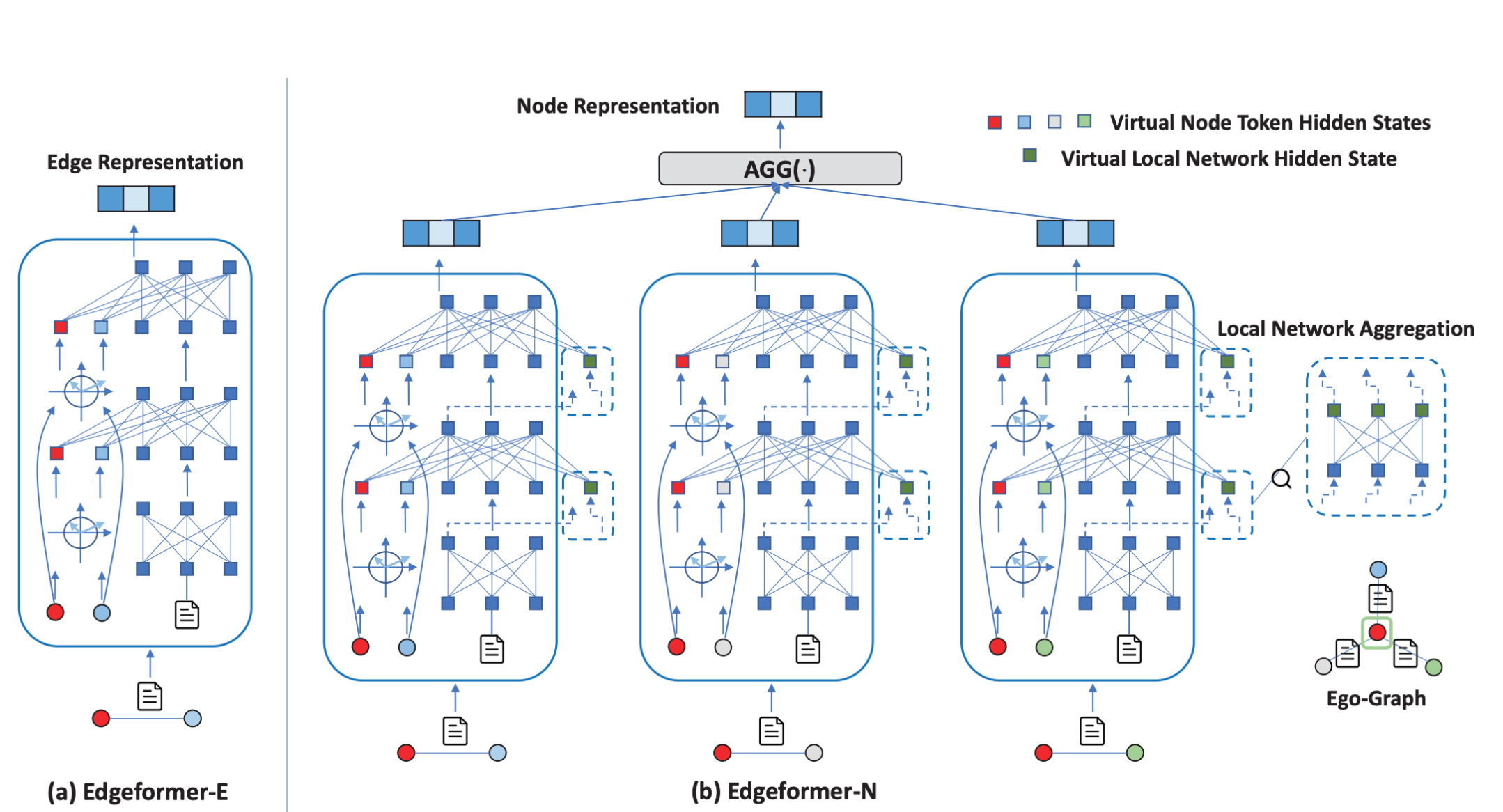
- 所提模型 Edgeformers包括:a. Edgeformer-E b.Edgeformer-N
a.Edgeformer-E是为提取Edge表征所设计。在-E中,对于两个节点和一条边来说,首先节点的初始表征为$z^{(0)}{v{i}}$,通过线性映射$W_n^{(l)}$,得到$z^{(l)}{v{i}}$(也可以采用GNNs来获取下一层的节点表征,在本文中这里的z不叫节点表征,而是virtual node tokens)。对于边上的文本,用PLM来提取包含语义信息的表征,然后将所有在该层得到的表征拼接,即得到该层的Edge 表征:
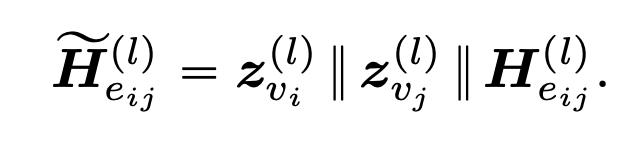
b. Edgeformer-N为提取Node表征所设计,它是在-E 的基础上,除了在每一层提取z和$H_{e_{i,j}}^{(l)}$,另外再通过节点的局部网络结构来进一步增强所提取的Edge表征。所谓的用局部网络结构来增强(Enhance)Edge表征,也就是说,既然节点表征是直接将与之相连的边的边表征进行聚合,那么这些边之间也可以进行一种相互作用来相互辅助提升彼此的表征。举个例子,给定一个关于 “Transformer “的对话和他们的参与者对以 “Machine Learning”为中心的其他对话进行解释,”Transformer “一词更可能指的是深度学习架构而不是变形金刚这个电影。我认为是合理的。因此,在Edgeformer-N中,所得到的该层的Edge表征就是:
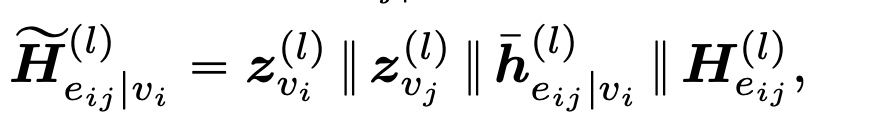
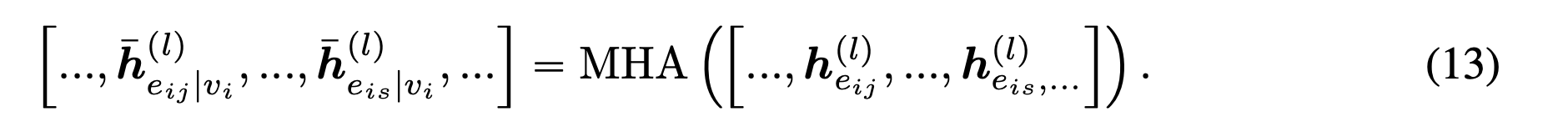

得到Edge表征后,用最直接的聚合从而得到Node表征:
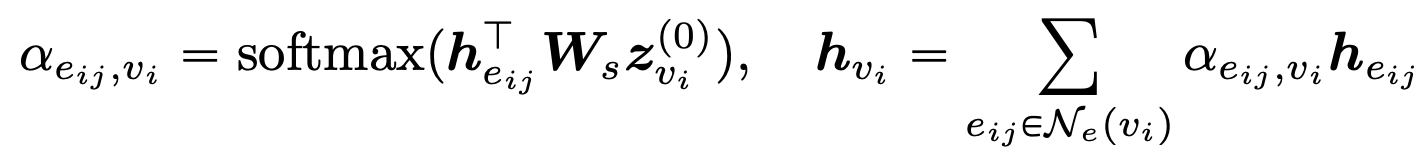
- 模型如何训练?
模型分为两个部分,两个部分分别采用不同的训练方式。Edgeformer-E采用supervised training,损失函数为标准的交叉熵损失;Edgeformer-N采用unsupervised training,损失函数为标准对比学习损失。分别如下:

- 所提的模型的优势是什么?缺点有哪些?
我认为本文提出的模型,是专注于边上有丰富语义信息的任务,比如在社交网络、信息网络中进行边分类和链路预测。本文的模型,通过PLM(e.g. BERT)能够很好的提取到边上的语义信息,从而得到具有语义信息的高质量的边表征,再基于此高质量边表征得到节点表征。在提取节点表征的-N阶段,引入了局部结构网络来进一步增强Edge表征,这样做就让所提的模型Edgeformer-N也类似于一种GNNs,因为(13)提取的表征这一步就可以看做是GNNs里的propagation步骤,聚合边表征得到节点表征可以看做是GNNs里的aggregation步骤。
缺点我觉得也很明显,就是时间复杂度仍然比较高,且专用程度太高(就是为边上有丰富语义信息的网络所设计)不够general。