
Graph Propagation Transformer for Graph Representation Learning
Published:
Graph Propagation Transformer for Graph Representation Learning[IJCAI2023]

- 研究的背景、目前方法存在哪些缺点
图表示学习大致有两大类:第一类主要集中在对图数据执行图神经网络(GNN)。这些方法遵循卷积模式来定义图数据中的卷积运算,并设计有效的邻域聚合方案,通过融合节点和图拓扑信息来学习节点表示。如GCN,以及GCN的各种变种。第二种方法是在transformer体系结构的基础上建立图模型。如Graphormer[微软](将图的结构和边缘特征转化为注意力偏差)。本文主要是关注第二类,基于Transformer架构的图网络。作者指出目前存在的Transformer-style的图网络主要有两个问题,①未显示(explicitly)利用图数据里节点和边的关系;②Transformer Block中的dual-FFN结构效率不高
- 研究的动机Motivation
作者觉得显式的利用node和edge间的关系对模型的性能有帮助,并且通过修改原始Transformer Block中的dual-FFN来提高效率。
- 如何解决问题的,有什么优势,又会有哪些缺点?
①在Graph Embedding层,提取Graph中的节点表征和边表征。本文参考Graphormer定义了节点表征x_node和x_edge:(实现也几乎就是照搬Graphormer)
$x_{node} = x_ + x_{deg-} + x_{deg+}$ 【节点表征 = 节点属性表征 + 出度表征 + 入度表征】
$x_{edge} = x_{edge_atrr} + x_{relative_pos}$ 【边表征 = 边属性表征 + 节点对相对位置表征】
其中的relative position也是沿用Graphormer中使用最短路径距离(shortest path distance)的编码来表示的。
②实现了GPA(Graph Propagation Attention),一种新的注意力机制,它显式地建立了node-to-node, node-to-edge, edge-to-node三种信息传播的路径。通过这种新的注意力机制,能够在每一个Transformer Block里优化edge 嵌入,然后更新过后的edge嵌入被送入下一个Transformer Block,这样可以自适应地学习不同的方式来利用边的特征和传播信息,这是一种比Graphormer更灵活的图表示学习方式。(Graphormer中是将边属性和空间位置编码作为attention的bias在每一个Transformer Block中共享的)
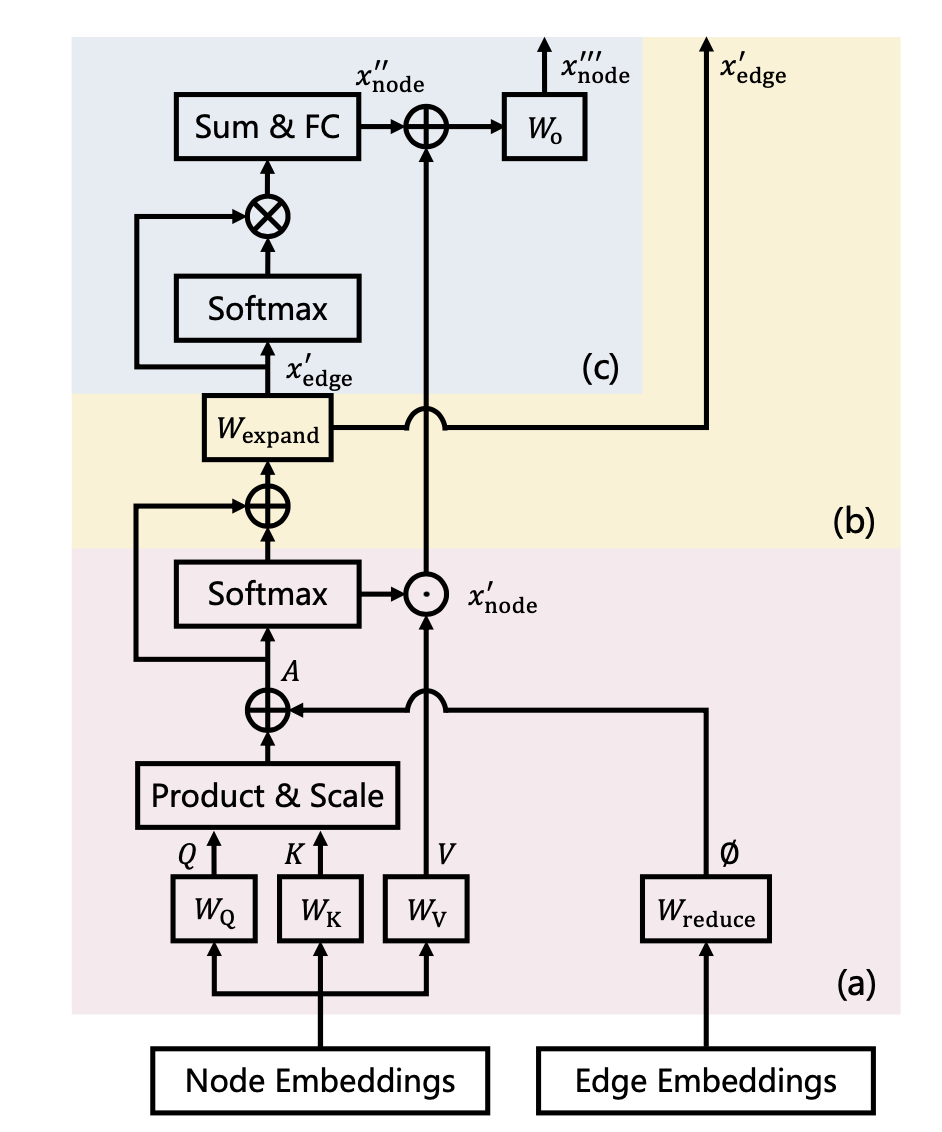


整个模型显式地利用了node和edge特征,并专门为此设计了一种全新注意力机制(GPA),使得node表征和edge表征在每一个Transformer Block中都能交互,且能够在每一层Transformer Block中都优化edge embedding,将更新过后的edge嵌入被送入下一个Transformer Block,这样可以自适应地学习不同的方式来利用边的特征和传播信息,这是一种比Graphormer更灵活的图表示学习方式。通过这种设计,GPTrans舍弃掉了低效率的传统Transformer中的dual-FFN,提高了计算效率。 模型做了3个level的任务,graph-level, node-level, and edge-level.①graph-level:有regress化学性质、有分子属性预测 ②node-level: node classification ③ edge-level: edge classification
不足之处:GPTrans沿用了Graphormer的大致思想,还是利用的是global attention mechanism。节点之间都要两两计算注意力得分复杂度依旧是很高的。对于节点表征并没有显式地利用位置编码。